Introduction 🎯
Machine Learning (ML) is transforming industries, from healthcare to finance, by enabling computers to learn from data. However, not all ML methods are the same. The two most common types are supervised learning and unsupervised learning.
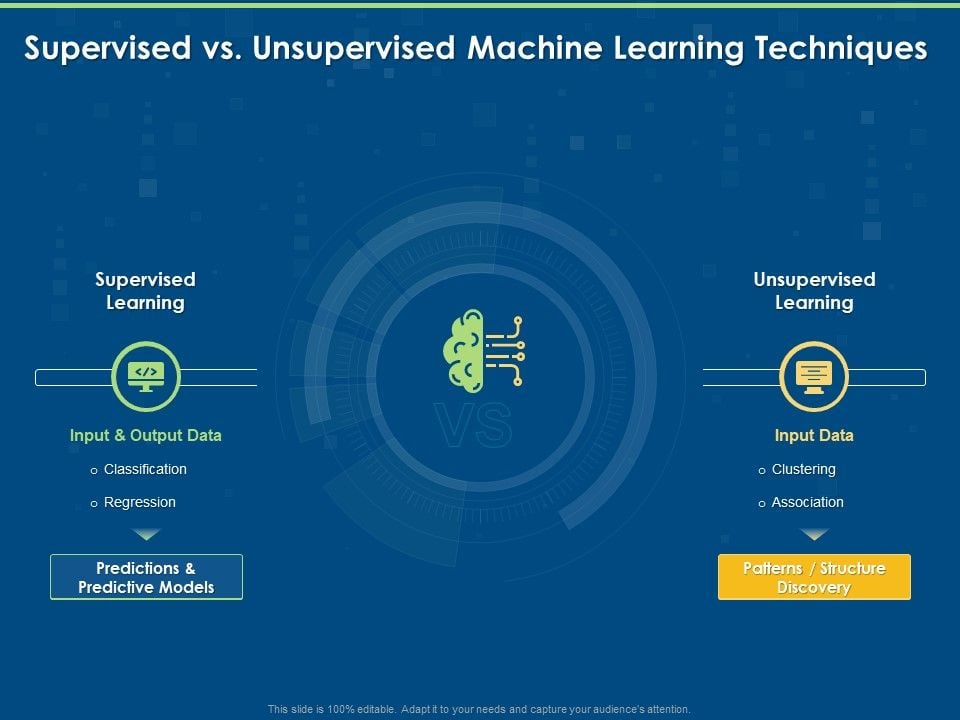
- Supervised Learning 🏫 – The model learns from labeled data.
- Unsupervised Learning 🕵️ – The model discovers patterns in unlabeled data.
Understanding their differences is crucial for selecting the right approach for a given problem. Let’s dive in! 🚀
1. What is Supervised Learning? 🎓
Definition 📖
Supervised learning is an ML approach where the model is trained using labeled data, meaning each input comes with a corresponding output. The goal is for the model to learn the relationship between inputs and outputs and make accurate predictions on new data.
How It Works ⚙️
- Training Data – The dataset consists of input-output pairs (e.g., images of cats 🐱 and dogs 🐶 labeled as “cat” or “dog”).
- Learning Process – The model identifies patterns in the training data.
- Prediction – The trained model predicts outputs for unseen inputs.
- Evaluation – Performance is measured using metrics like accuracy, precision, recall, and loss functions.
Types of Supervised Learning 📂
🔹 Classification – Predicts categories (e.g., email spam detection: “Spam” or “Not Spam”).
🔹 Regression – Predicts continuous values (e.g., house price prediction based on features).
Example of Supervised Learning 🔍
Consider training a model to recognize handwritten digits (0-9) ✍️:
- Input: Image of a digit
- Output: Corresponding number (e.g., “5”)
- Algorithm: Neural Networks, Decision Trees, or Support Vector Machines
2. What is Unsupervised Learning? 🕵️♂️
Definition 📖
Unsupervised learning involves training a model on unlabeled data. The goal is to find hidden patterns, relationships, or structures in the data without explicit instructions.
How It Works ⚙️
- Input Data – The dataset has no predefined labels (e.g., customer purchase history).
- Pattern Discovery – The model groups similar data points or finds underlying structures.
- Insight Extraction – Used for customer segmentation, anomaly detection, etc.
Types of Unsupervised Learning 📂
🔹 Clustering – Groups data points based on similarity (e.g., customer segmentation).
🔹 Dimensionality Reduction – Reduces dataset size while preserving important information (e.g., PCA in image compression).
Example of Unsupervised Learning 🔍
A company wants to segment its customers based on purchasing behavior:
- Input: Transaction data (no predefined categories)
- Output: Groups of similar customers (e.g., frequent buyers vs. occasional shoppers)
- Algorithm: K-Means Clustering, Hierarchical Clustering
3. Key Differences Between Supervised and Unsupervised Learning ⚖️
| Feature | Supervised Learning 🎓 | Unsupervised Learning 🕵️ |
|---|---|---|
| Data Type | Labeled data ✅ | Unlabeled data ❌ |
| Main Goal | Make predictions 📊 | Discover patterns 🔍 |
| Types | Classification, Regression | Clustering, Dimensionality Reduction |
| Example | Spam detection 📧 | Customer segmentation 🏢 |
| Human Intervention | High (labels needed) 🙋♂️ | Low (self-discovery) 🤖 |
| Complexity | Easier to interpret 🧐 | Harder to explain 🤷♂️ |
4. Algorithms Used in Each Approach 🏗️
Supervised Learning Algorithms 🏆
- Linear Regression – Predicts continuous values (e.g., stock prices 📈).
- Logistic Regression – Binary classification (e.g., “Yes” or “No” outcomes ✅❌).
- Decision Trees – Hierarchical decision-making (e.g., diagnosing diseases 🏥).
- Random Forest – Multiple decision trees for improved accuracy 🌲.
- Support Vector Machines (SVM) – Finds best decision boundary between categories 📊.
- Neural Networks – Deep learning models used for image recognition 🖼️.
Unsupervised Learning Algorithms 🏆
- K-Means Clustering – Groups similar data points (e.g., market segmentation 💼).
- Hierarchical Clustering – Builds a tree of clusters for better analysis 🌳.
- Principal Component Analysis (PCA) – Reduces dataset dimensions while keeping important features 📉.
- Autoencoders – Neural networks used for data compression and anomaly detection 🔄.
- GANs (Generative Adversarial Networks) – Generates realistic synthetic data 🖼️.
5. Real-World Applications 🌍
Supervised Learning in Action 🚀
✅ Email Spam Detection – Classifying emails as spam or not 📩.
✅ Credit Scoring – Predicting whether a person will default on a loan 💳.
✅ Medical Diagnosis – Identifying diseases based on symptoms 🏥.
✅ Voice Recognition – Converting speech to text (e.g., Siri, Alexa) 🎙️.
✅ Self-Driving Cars – Detecting pedestrians and traffic signs 🚗.
Unsupervised Learning in Action 🔎
✅ Customer Segmentation – Grouping shoppers based on behavior 🛒.
✅ Anomaly Detection – Fraud detection in banking transactions 💰.
✅ Market Basket Analysis – Finding shopping patterns for recommendations 🏪.
✅ Social Media Analysis – Identifying communities in social networks 📱.
✅ Biology & Genetics – Identifying DNA patterns 🧬.
6. When to Use Which Approach? 🤔
🔹 Use Supervised Learning when:
- You have labeled data 📌.
- You need accurate predictions 📈.
- You want to classify objects (e.g., spam filters, medical diagnoses).
🔹 Use Unsupervised Learning when:
- Your data is unlabeled 🚀.
- You want to discover hidden patterns 🔍.
- You need to segment data (e.g., customer clusters).
Conclusion 🎯
Both supervised and unsupervised learning play crucial roles in Machine Learning. Supervised learning is best for predictive tasks, while unsupervised learning excels at discovering hidden patterns in data. By understanding their differences, you can choose the right approach for your problem and make better data-driven decisions!

