In recent years, the field of Natural Language Processing (NLP) has undergone a dramatic transformation thanks to a powerful deep learning architecture known as the Transformer. Introduced in a seminal 2017 paper by Vaswani et al., titled “Attention Is All You Need”, Transformers have become the cornerstone of modern NLP systems, powering technologies from chatbots to machine translation, text summarization, and language generation. Let’s explore what makes Transformers so revolutionary, how they work, and why they’ve reshaped the landscape of artificial intelligence 🧠📈.
A Brief History of NLP Models 📜🧑💻
Before the Transformer, NLP was primarily dominated by sequential models such as:
-
Recurrent Neural Networks (RNNs) 🔁
-
Long Short-Term Memory networks (LSTMs) 🧬
-
Gated Recurrent Units (GRUs) 🔄
These models processed data one step at a time, making them inherently sequential and slow. While they were groundbreaking in their own right, they struggled with long-range dependencies, parallel processing inefficiencies, and vanishing gradient problems in deep sequences. This made them less suitable for large-scale or real-time language tasks ⏳🧱.
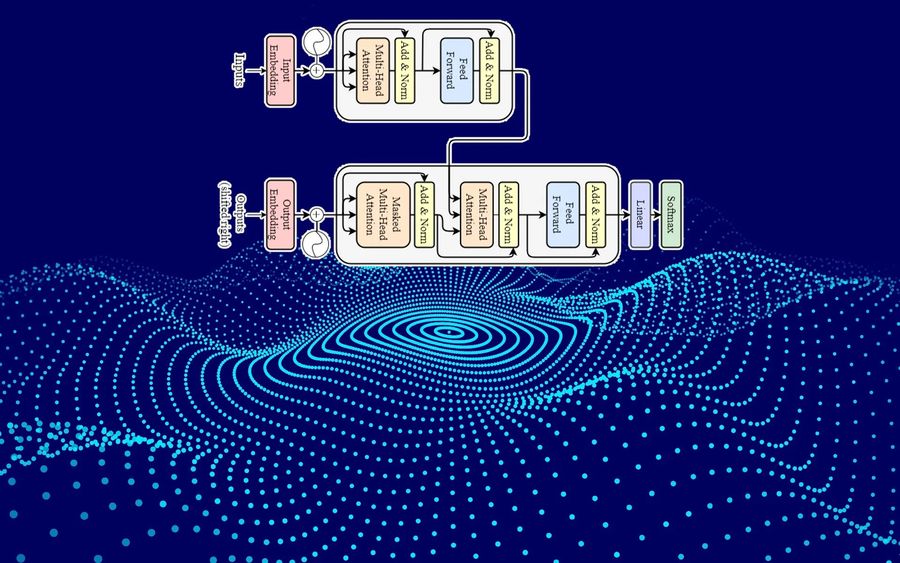
Enter the Transformer: “Attention Is All You Need” 🎯⚙️
The Transformer architecture flipped the paradigm by removing recurrence entirely. Instead, it introduced a new mechanism: self-attention 💡.
At its core, a Transformer model allows each word (or token) in a sentence to attend to every other word, regardless of their position. This results in:
✅ Better context understanding
✅ Improved ability to model long-range relationships
✅ Massively parallel training on GPUs
The primary components of a Transformer include:
-
Self-Attention Mechanism: Determines which words in a sequence are important to others 🧲
-
Multi-Head Attention: Allows the model to focus on different parts of a sentence simultaneously 🧠🕵️♂️
-
Feedforward Neural Networks: Applies transformations independently to each position in the sequence 🧱
-
Positional Encoding: Adds information about word order that is otherwise lost due to non-sequential architecture ⏺️🔢
The Power of Self-Attention 🔍🕸️
The key innovation lies in self-attention, which enables the model to weigh the relevance of different words when generating representations. For example, in the sentence:
“The cat sat on the mat because it was tired.”
The model must understand that “it” refers to “the cat.” Traditional RNNs might struggle here due to the distance between the pronoun and its antecedent. Transformers, however, handle this with ease by attending globally across the sentence 🌍✨.
Training at Scale: The Age of Large Language Models 📚🌐
Thanks to their scalability, Transformers paved the way for massive pre-trained models like:
-
BERT (Bidirectional Encoder Representations from Transformers) 📖
-
GPT (Generative Pre-trained Transformer) 🗣️
-
T5 (Text-To-Text Transfer Transformer) 🔁
-
RoBERTa, XLNet, and more 🚀
These models are pre-trained on vast corpora of text and fine-tuned for specific tasks. This means that rather than building task-specific models from scratch, developers can leverage general-purpose language models and adapt them quickly 💼⚡.
This shift has made NLP more accessible, efficient, and powerful across industries, from healthcare and finance to education and entertainment 🎬💰🏥.
Transformers vs. Traditional Models: A Comparison Table 📊
| Feature | Traditional (RNN/LSTM) | Transformer |
|---|---|---|
| Processing | Sequential | Parallel |
| Long-Range Dependency | Weak | Strong |
| Scalability | Limited | Excellent |
| Training Speed | Slow | Fast |
| Context Awareness | Limited | Rich |
Real-World Applications of Transformers 🌍🛠️
Transformers have revolutionized a wide range of applications:
-
Machine Translation (e.g., Google Translate) 🌎🔁
-
Text Generation (e.g., ChatGPT, Jasper) ✍️🗨️
-
Sentiment Analysis (e.g., understanding reviews) 💬❤️💔
-
Question Answering (e.g., SQuAD, virtual assistants) ❓🤖
-
Text Summarization (e.g., summarizing news or reports) 📰📉
These tools not only process language faster and more accurately but also generate more human-like and contextually appropriate responses 🧑🏫🧑💻.
The Future of NLP with Transformers 🚀🔮
As Transformer-based architectures continue to evolve, we’re seeing even more powerful innovations:
-
Multimodal Models: Combining text with images, audio, and video 🎥📷📝
-
Efficient Transformers: Like Longformer and Reformer, reducing computational costs ⚡💡
-
Ethical NLP: Building models that are fair, explainable, and responsible 🤝⚖️
Moreover, the introduction of open-source platforms like Hugging Face and advancements in transfer learning have democratized access to cutting-edge NLP capabilities, enabling anyone from students to enterprises to build transformative language applications 🏛️🏢👩🎓.
Conclusion: A New Era in Language Intelligence 📖🌈
The Transformer architecture has fundamentally changed how we build and use language models. Its ability to understand context deeply, process data in parallel, and scale to enormous datasets has made it the gold standard in NLP.
From helping virtual assistants understand your queries to enabling machines to write poetry, the Transformer isn’t just a technical innovation—it’s a leap toward truly intelligent communication between humans and machines 🤝🧠💬.
Whether you’re a developer, researcher, or simply a curious mind, understanding how Transformers work is key to unlocking the future of human-AI interaction 🔓🤖.